Robust Policies via Mid-Level Visual Representations
Abstract
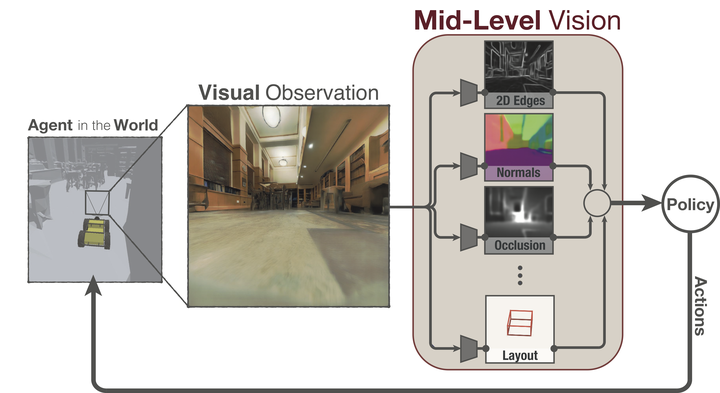
Vision-based robotics often separates the control loop into one module for perception and a separate module for control. It is possible to train the whole system end-to-end (e.g. with deep RL), but doing it ‘from scratch’ comes with a high sample complexity cost and the final result is often brittle, failing unexpectedly if the test environment differs from that of training. We study the effects of using mid-level visual representations (features learned asynchronously for traditional computer vision objectives), as a generic and easy-to-decode perceptual state in an end-to-end RL framework. Mid-level representations encode invariances about the world, and we show that they aid generalization, improve sample complexity, and lead to a higher final performance. Compared to other approaches for incorporating invariances, such as domain randomization, asynchronously trained mid-level representations scale better: both to harder problems and to larger domain shifts. In practice, this means that mid-level representations could be used to successfully train policies for tasks where domain randomization and learning-from-scratch failed. We report results on both manipulation and navigation tasks, and for navigation include zero-shot sim-to-real experiments on real robots.
Supplementary notes can be added here, including code and math.